Please double-click to open
What's Big data?
- A large quantum of data
- Collected unresistant from digital relations
- With great variety and a high rate of haste
- The big data course syllabus plays an important part in machine literacy and analytics.
Big data analytics
The age of big data is now coming. But the traditional data analytics may not be suitable to handle similar large amounts of data. The question that arises now is, how to develop a high-performance platform to efficiently assay big data and how to design an applicable mining algorithm to find the useful effects of big data.
Big Data made changes in traditional data analysis platforms. To perform any kind of analysis on similar substantial and complex data, spanning up the tackle platforms becomes imminent, and choosing the right tackle/ software platforms becomes a pivotal decision if the stoner’s conditions are to be satisfied in a reasonable quantum of time Generally, when someone has to decide on the right platforms to choose from, he will have to probe what their algorithm requirements are. One will come across many abecedarian issues in their mind before making the right opinions.
- How snappily do we need to get the results?
- How big is the data to be reused?
- Does the model structure bear several duplications or a single replication?
Easily, these enterprises are operation/ algorithm dependent that one needs to address before analyzing the systems/ platform- position conditions. At the position of the system, one has to strictly look into the following enterprises
- Will there be a need for further data processing capability in the future?
- Is the rate of data transfer critical for this operation?
- Is there a need for handling tackle failures within the operation?
For all the below questions, the below big data course mind map gives the answers.

Machine Literacy on big data course training syllabus holds the below:
Big data enables ML algorithms to uncover further fine-granulated patterns and make further timely and accurate prognostications than ever ahead, on the other hand, it presents major challenges to ML similar to model scalability and distributed calculating The arrival of the big data period has prodded broad interest in ML. ML algorithms have noway been better promised and also challenged by big data in gaining new perceptivity into colorful business operations and mortal behaviors. On one hand, big data provides unprecedentedly rich information for ML algorithms to prize underpinning patterns and to make prophetic models; on the other hand, traditional ML algorithms face critical challenges similar to scalability to truly unleash the retired value of big data. With an ever-expanding macrocosm of big data, ML has to grow and advance to transfigure big data into practicable intelligence.
Advantages of Big Data on ML
Big data presents new openings for ML. For case, big data enables pattern literacy at multi-granularity and diversity, from multiple views in an innately resemblant fashion. In addition, big data provides openings to make reasoning conclusions grounded on chains of sequence.
Challenges
Big data also introduces major challenges to ML similar as high data dimensionality, model scalability, distributed computing, streaming data, rigidity, and usability.
ML on big data (MLBiD) is centered on the machine learning component, which interacts with four other components, including big data, user, domain, and system. The interactions go in both directions. For instance, big data serve as inputs to the learning component and the latter generates outputs, which in turn become part of big data; the user may interact with the learning component by providing domain knowledge, personal preferences, and usability feedback, and by leveraging learning outcomes to improve decision making; domain can serve both as a source of knowledge to guide the learning process and as the context of applying learned models; system architecture has an impact on how learning algorithms should run and how efficient it is to run them, and simultaneously meeting the learning need may lead to a co-design of system architecture.
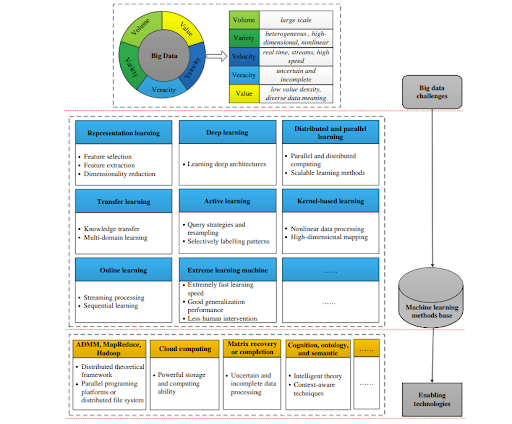
Big data has been characterized by five confines volume( volume/ quantum of data), haste( speed of data generation), variety( type, nature, and format of data), veracity( responsibility/ quality of captured data), and value( perceptivity and impact). We organized the five confines into a mound, conforming to big, data, and value layers starting from the bottom
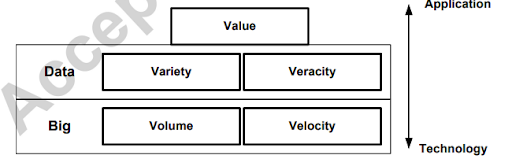
The big layer is the most fundamental and the data layer is central to big data, and the value aspect characterizes the impact of big data on real-world applications. The lower layer (e.g., volume and velocity) depends more heavily on technological advances, and the higher layer (e.g., value) is more oriented toward applications that harness the strategic power of big data. To realize the value of big data analytics and to process big data efficiently, existing ML paradigms and algorithms need to be adapted.
Conclusion:
Big data are now fleetly expanding in all wisdom and engineering disciplines. Learning from this massive data is anticipated to bring significant openings and transformative eventuality for colorful sectors. still, utmost traditional machine literacy ways aren't innately effective or scalable enough to handle the data with the characteristics of large volume, different types, high speed, query and space, and low-value viscosity. In response, machine literacy needs to resuscitate itself for big data processing.