Please double-click to open
Understanding Neural Networks
Deep learning was invented by Geoffrey Hinton in the 1980s. He is widely regarded as the founder of the deep learning field. Hinton has been with Google since March 2013 when his company, DNNresearch Inc., was acquired.
Hinton's major contribution to the field of deep learning was comparing machine learning techniques to the human brain.
The structure created by Hinton was called an artificial neural network (or artificial neural network for short). Here's a quick explanation of how they work:
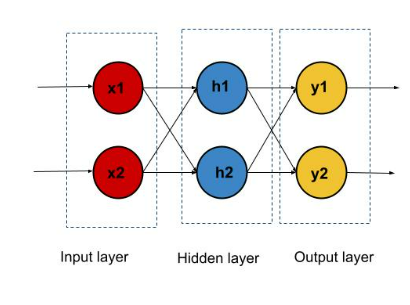
- Artificial neural networks are made up of layers
- The neurons in neural networks are designed to behave similar to Biological neurons
- There are three types of layers, input layer followed by hidden and output layer
- Each node in the neural network performs some type of computation that is propagated to other nodes in the neural network
In a deep learning network, each level of nodes trains a specific set of functions based on the output of the previous level. The deeper you dig into the neural network, the more complex the features a node can detect as it aggregates and recombines features from previous layers.
This is called the functional hierarchy, a hierarchy of increasing complexity and abstraction. This enables deep learning networks to handle very large, high-dimensional datasets with billions of parameters across nonlinear functions.
These neural networks are particularly good at discovering underlying structures in the unlabeled, unstructured data that make up the majority of the world's data. Another word for unstructured data is raw disk. namely photos, texts, videos, and audio recordings. Therefore, one of the problems deep learning best solves is processing and clustering the world's raw, unlabeled media, finding similarities in data that humans have never organized or named in relational databases. and anomaly detection.
For example, deep learning can take a million photos and group them by similarity. cats in one corner, an icebreaker in another corner, and one-third all pictures of my grandmother. This is the basis of so-called smart photo albums.
Apply the same idea to other data types. Emails full of angry complaints can accumulate in one corner of vector space, while happy customers and spambot messages can accumulate in another. It is the basis for various messaging filters and can be used in customer relationship management (CRM). The same applies to voice messages.
For time series, data can be concentrated on normal/healthy behaviour and abnormal/dangerous behaviour. Time-series data generated by smartphones provide insight into users' health and habits. It can be used to prevent catastrophic failures when produced by auto parts.
Deep learning networks perform automatic feature extraction without human intervention, unlike most traditional machine learning algorithms. Given that feature extraction is a task that takes teams of data scientists years to complete, deep learning is a way around the bottleneck for limited experts. Expand the power of small, inherently unscalable data science teams.
When training on unlabeled data, each node layer of a deep network iteratively tries to reconstruct the input from which it samples, finding the difference between the network's estimates and the probability distribution of the input data itself. By trying, it automatically learns the features. to minimise For example, the restricted Boltzmann machine creates so-called reconstructions in this way.
These neural networks develop the ability to identify correlations between specific pertinent features and the best outcomes; they connect feature signals to the features they represent, whether in a full reconstruction or with labelled data.
When applied to unstructured data after being trained on labelled data, a deep learning network has access to far more input than machine learning nets do. The more data a net can train on, the more accurate it is likely to be, which is a recipe for increased performance.
(Bad algorithms can outperform good algorithms when trained on very little data.) Deep learning has a clear edge over earlier algorithms since it can process and learn from enormous amounts of unlabeled data.
A deep learning network eventually becomes an output layer. Assigns probabilities to specific outcomes or labels in logistic or softmax classifiers. We call this forecasting, but it is forecasting in the broadest sense.
Given raw data in the form of an image, a deep-learning network may decide, for example, that the input data is 90 percent likely to represent a person.
When working with neural networks, the goal is to reach the point of minimum error as quickly as possible. We're racing, and the race is on a track, so we're looping over the same points over and over again. The start line of the race is where the weights are initialised, and the finish line is where these parameters provide sufficiently accurate classification and prediction.
The race itself has many steps and each of these steps is similar to the steps before and after. Just like a runner, you repeat your actions over and over again to reach your goal. Each step of the neural network involves estimation, error measurement, small updates of weights, and incremental adjustments of coefficients to slowly learn to pay attention to the most important features.
A set of weights, whether starting or ending, is also called a model. This is because it is an attempt to model the relationship between data and ground truth tags to explain the structure of data capture. Usually a model starts out bad, ends up not so bad, and changes over time as the neural network updates its parameters.
This is because neural networks are born in ignorance. We don't know which weights and biases will best transform the input to make a correct guess. Starting with a guess, learning from his mistakes, he must try to make one better guess at a time. (You can think of a neural network as a miniature version of the scientific method, where hypotheses are tested and retried. It's just a blindfolded scientific method. Or like a child: Born without much knowledge and exposed to life experience, they slowly learn to solve the world's problems.)
Here is a brief description of what happens during training in a feedforward neural network. The easiest architecture to explain.
entries enter the network. Coefficients or weights relate this input to the set of guesses that the network ultimately makes.
input * weight = guess
A weighted input leads to guesses about what that input is. The neural then makes a guess, compares it to the ground truth of the data.
ground truth - guess = error
The difference between a network guess and the truth is its error. The network measures this error, feeds it back through its model, and adjusts the weights to the extent that they contributed to the error.
error * weight's contribution to error = adjustment
The three pseudo-formulas above take into account three important functions of a neural network: scoring the inputs, computing the loss, and applying the update to the model - again starting the three-step process. A neural network is a corrective feedback loop that rewards weights that support correct guesses and penalises weights that lead to mistakes.
In a few circles, neural networks are synonymous with AI.Others consider it a "brute force" technique characterised by a lack of intelligence as it starts from a clean slate and hammers out an accurate model. According to this interpretation, neural networks are an effective but inefficient modelling approach. This is because neural networks make no assumptions about the functional dependencies between outputs and inputs.
After all, major AI research groups are pushing the pinnacle of the field by training increasingly large-scale neural networks. Brute force works. This is a necessary but not sufficient condition for AI breakthroughs. OpenAI's push towards more general AI highlights brute force approaches that have proven effective in well-known models like GPT-3.
Algorithms like Hinton's Capsule Network require far fewer data instances to converge to an accurate model. That said, current research has the potential to address brute force inefficiencies in deep learning.
Neural networks are useful as function approximators, mapping inputs to outputs in many perceptual tasks for more general intelligence, but they are often combined with other AI techniques to perform more complex tasks. can also do. For example, deep reinforcement learning incorporates neural networks into a reinforcement learning framework to combine actions and rewards to achieve goals. Deepmind's victory at the video game and board game AlphaGo is a good example.